|
TUTORIALS:
|
Subtracting Rational Expressions with the Same
Denominator
Subtracting rational expressions with the same denominator is like
subtracting fractions with the same denominator.
Procedure —
To Subtract Rational Expressions with the Same Denominator
Step 1 Subtract the numerators.
Write the difference as the numerator over the common
denominator.
Step 2 Reduce to lowest terms.
Note:
Here’s an example of subtracting
fractions:
Subtract and write the answer in lowest
terms:
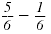
The denominators are the same.
Subtract the numerators and write the
difference over the common denominator,
6.
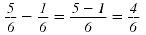
To reduce, cancel the common factor, 2, in
the numerator and denominator.
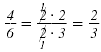
Thus,
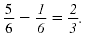
Example 1
Find:
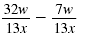
Solution
| The denominators are the same.
|
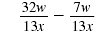 |
| Step 1 Subtract the numerators. Write the
difference as the numerator over the
common denominator. |
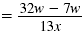 |
| Combine the like terms in the numerator. |
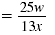 |
| Step 2 Reduce to lowest terms.
|
|
| First, factor the numerator and denominator. |
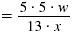 |
| There are no common factors to cancel. |
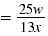 |
Thus,
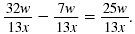
Example 2
Find:
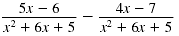
Solution
| The denominators are the same.
|
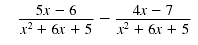 |
| Step 1 Subtract the numerators. Write
the difference as the numerator
over the common denominator. |
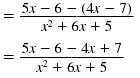 |
| Combine the like terms in the
numerator.
|
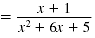 |
| Step 2 Reduce to lowest terms.
|
|
| First, factor the numerator and
denominator.
|
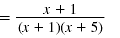 |
| Next, cancel the common factor,
x + 1. |
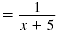 |
Thus,
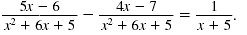
|

